Everything You Need To Know About Knowledge Distillation, aka Teacher-Student Model
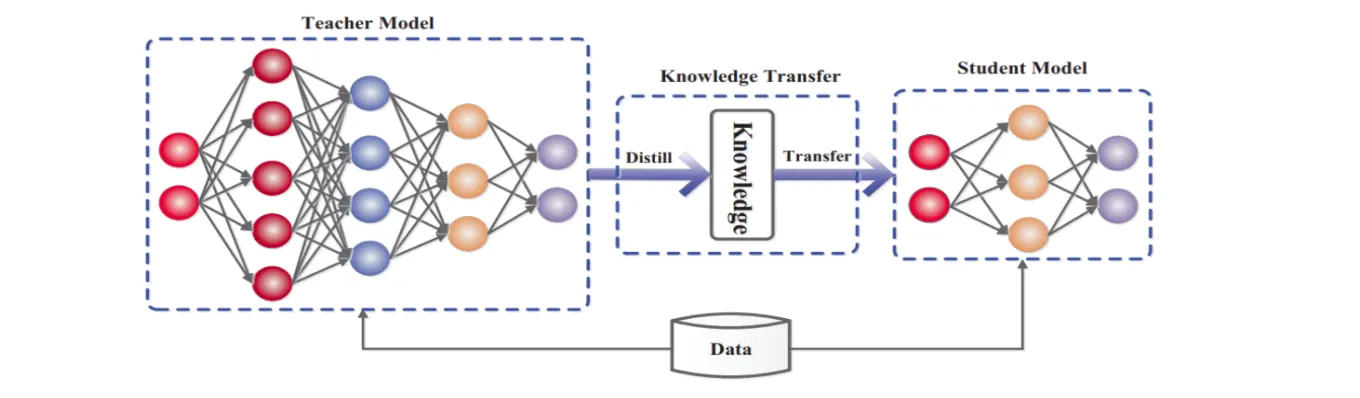
Knowledge distillation refers to the process of transferring knowledge from a large model to a smaller one. This is vital because the larger knowledge capacity of bigger models may not be utilized to its full potential on its own. Even if a model only employs a small percentage of its knowledge capacity, evaluating it can be computationally expensive. Knowledge distillation is the process of moving knowledge from a large model to a smaller one while maintaining validity.
As illustrated in the figure above, knowledge distillation involves a small “student” model learning to mimic a large “teacher” model and using the teacher’s knowledge to achieve similar or superior accuracy.
Need for Knowledge Distillation
The size of neural networks is enormous (millions/billions of parameters), necessitating the use of computers with significant memory and computation capability to train/deploy them.
In most cases, models must be implemented on systems with little computing power, such as mobile devices and edge devices, in various applications.
However, ultra-light (a few thousand parameters) models may not provide us with good accuracy. This is where Knowledge Distillation comes into play — with assistance from the instructor network, it essentially lightens the model while keeping accuracy.
Real-life Applications for Knowledge Distillation
To understand how knowledge distillation works in real life, let’s take the example of self-driving cars. The deep learning model used in the image recognition system for self-driving cars, which is based on a convolutional neural network (CNN), has a very high accuracy rate, but it’s too large to be deployed in the cars themselves due to its computational and memory requirements.
To overcome this issue, knowledge distillation can be used to transfer the knowledge learned by the CNN to a smaller, more efficient model, such as a MobileNet or SqueezeNet. The distilled model will be trained to mimic the output of the CNN on a set of labeled training images.
During training, the loss function will not only consider the difference between the output of the distilled model and the ground truth labels but also the difference between the output of the distilled model and the output of the CNN for the same input.
Once the distilled model is trained, it can be deployed in self-driving cars, where it will require less computational resources and memory compared to the original CNN, while still maintaining a high level of accuracy in recognizing objects and traffic signs.
This model can be replicated in many other places — speech recognition on mobile devices being one of them. With AI/ML coming to the forefront, the list of systems adopting the knowledge distillation model will expand fast.
Types of Knowledge Distillation
Not all knowledge distillation models are created equal, and their structure plays a key role in determining their application. For greater clarity on their usability, let’s take a look at the different types of knowledge distillation:
Response-based Knowledge Distillation

Response-based knowledge distillation captures and transfers information from the output layer (predictions) of the teacher network, and the student network directly mimics these final predictions by minimizing the distillation loss.
For example, in natural language processing, a large model may be trained to generate responses to input sentences. This approach can be computationally expensive and impractical for deployment on devices with limited resources. Instead, a smaller student model can be trained using the response outputs of the larger model as targets. The student model is then trained to generate similar responses to the input sentences as the larger model.
Use Case: machine translation, chatbots, and question-answering systems.
Feature-based Knowledge Distillation

A trained teacher model also captures data knowledge in its intermediate layers, which is particularly important for deep neural networks. The intermediate layers learn to discriminate between specific features, which can then be used to train a student model.
For example, in image recognition, a large model may be trained to recognize images by analyzing every pixel in the image. This approach can be computationally expensive and impractical for deployment on devices with limited resources. Instead, a smaller student model can be trained using only the most important features of the input image, such as color gradients. These features are extracted from the image using the larger teacher model and then used to train the student model
Use Case: object detection, natural language processing, and speech recognition
Relation-based Knowledge Distillation

In addition to knowledge represented in the output layers and the intermediate layers of a neural network, the knowledge that captures the relationship between feature maps can also be used to train a student model. This form of knowledge is termed relation-based knowledge. This relationship can be modeled as the correlation between feature maps, graphs, similarity matrices, feature embeddings, or probabilistic distributions based on feature representations.
For example, in image recognition, a large model may be trained to recognize objects in images by analyzing the relationships between different parts of the image, such as edges, textures, and shapes. This approach can be computationally expensive and impractical for deployment on devices with limited resources. Instead, a smaller student model can be trained to learn the same relationships between the input data and the output responses, but with fewer parameters and computations.
Use Cases: object detection and scene segmentation
Modes of Distillation
Knowledge distillation can be done in the following ways:

Offline Distillation
Offline distillation is the most common method, where a pre-trained teacher model is used to guide the student model. In this scheme, the teacher model is first pre-trained on a training dataset, and then knowledge from the teacher model is distilled to train the student model.
Given the recent advances in deep learning, a wide variety of pre-trained neural network models are openly available that can serve as the teacher depending on the use case. Offline distillation is an established technique in deep learning and is easier to implement.
For example, in object recognition, a teacher model may be trained on a large dataset of images, and its soft targets (probability distributions over the class labels) are stored for each image. The student model is then trained on a smaller dataset of images, using the soft targets from the teacher model as the labels. This allows the student model to learn from the teacher’s knowledge and capture the more nuanced relationships between the objects, even with a limited amount of training data.
Online Distillation
In offline distillation, the pre-trained teacher model is usually a large-capacity deep neural network. For several use cases, a pre-trained model may not be available for offline distillation. To address this limitation, online distillation can be used where both the teacher and student models are updated simultaneously in a single end-to-end training process. Online distillation can be operationalized using parallel computing thus making it a highly efficient method.
For example, in online recommender systems, a teacher model may be pre-trained on a large dataset of user preferences and used to generate recommendations for each new user. The student model is then trained on these recommendations, along with the user’s actual preferences, to learn from the teacher’s knowledge in real-time and improve the accuracy of its recommendations.
Self-Distillation
In self-distillation, the same model is used for the teacher and the student models. For instance, knowledge from deeper layers of a deep neural network can be used to train the shallow layers. It can be considered a special case of online distillation and instantiated in several ways. Knowledge from earlier epochs of the teacher model can be transferred to its later epochs to train the student model.
For example, in image recognition, a model may be trained on a dataset of images and their true labels and then used to make predictions on the same dataset. These predictions are then used as soft targets to retrain the model, which is then used to make better predictions on the same dataset. This process is repeated multiple times, with the model using its own predictions as the teacher to improve its own accuracy
Modern deep learning applications are based on cumbersome neural networks with large capacity, memory footprint, and slow inference latency. Deploying such models to production is an enormous challenge. Knowledge distillation is an elegant mechanism to train a smaller, lighter, faster, and cheaper student model that is derived from a large, complex teacher model.
